
Data Power Meets AI Power In a Virtuous Loop

AI runs on data—nothing groundbreaking there, even if the extent to which this is true has been demonstrated by the work done on transformer models.

Myles Younger made a great comment when I posted this representation:

He’s absolutely right—it’s a virtuous cycle! Just as AI is powered by data, data can also be enhanced and refined through AI.
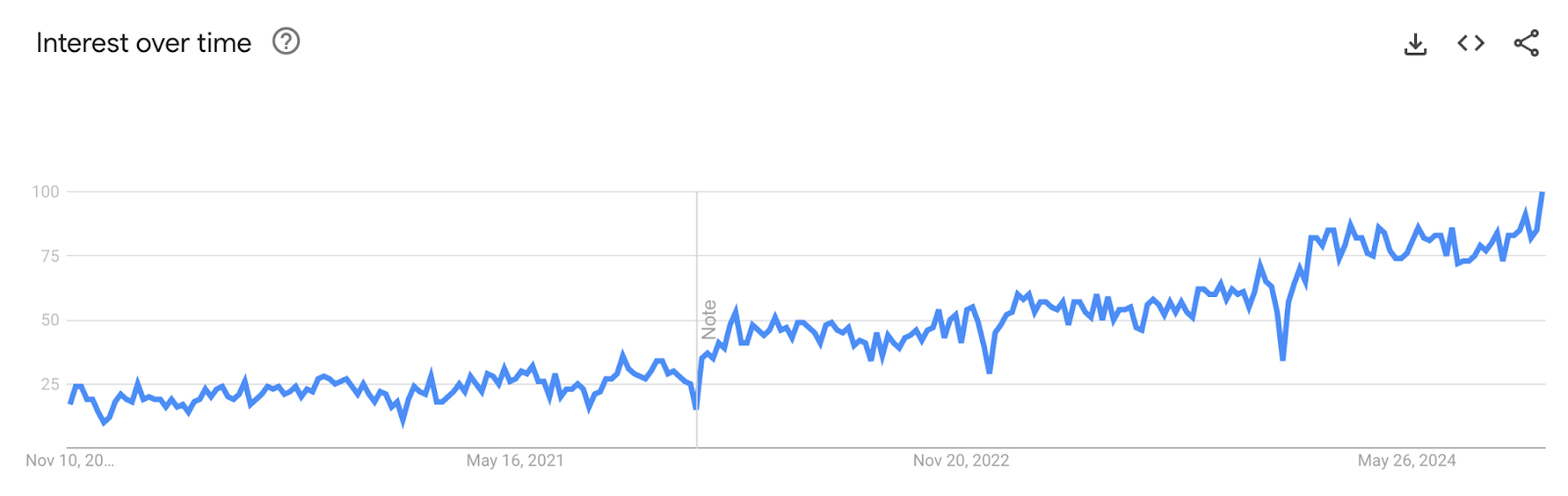
AI can not only use data but also generate—or transform—it. Over the past few years, the concept of synthetic data1 has gained significant traction, take a look at this search trends chart:
Data^AI and AI^Power: To Infinity and Beyond?
It’s fascinating how my initial goal was to convey a simple concept, yet it quickly evolved into a thought experiment that flipped my perspective upside down. It got me thinking—is it really this simple and infinite?
A linear-ish representation assumes that more data will continue to improve AI at a rapid pace and that “more” AI can likewise enhance data indefinitely. But is that truly the case?
Let’s explore both angles:
1. AI Improvement
Spoiler alert: A recent article from The Information highlighted potential concerns from OpenAI regarding whether a GPT-5 model would deliver the same leap in improvement as the jump from GPT-3 to GPT-4. Despite leveraging significantly larger datasets for training, it suggests there may be diminishing returns in scaling data for AI advancements.
2. Data Improvement
AI can help transform data: cleaning up and standardizing mailing addresses or even generating synthetic data to support specific use cases, such as optimizing campaign performance. But here’s the catch—what happens as AI models begin to plateau against standard benchmarks? For instance, how significant is the difference between a model achieving 90% accuracy versus one reaching 95% for a particular task related to data improvement? Granted, this doesn’t apply to scenarios where accuracy is the ultimate priority, but for many use cases, the law of diminishing returns seems to be creeping in here too.
Perfection May Not Be Attainable—And That’s Okay
If progress isn’t perfectly linear, what would be a better way to represent the relationship between AI and data as they improve the quality of one another?
Let’s nerd out for a moment. While acknowledging this model won’t be perfect, I’ve defined two functions: QAI(x) and QData(x). These represent the respective quality of AI and Data within an organization, with incremental improvements denoted by ΔQ(x). The functions are defined as follows:
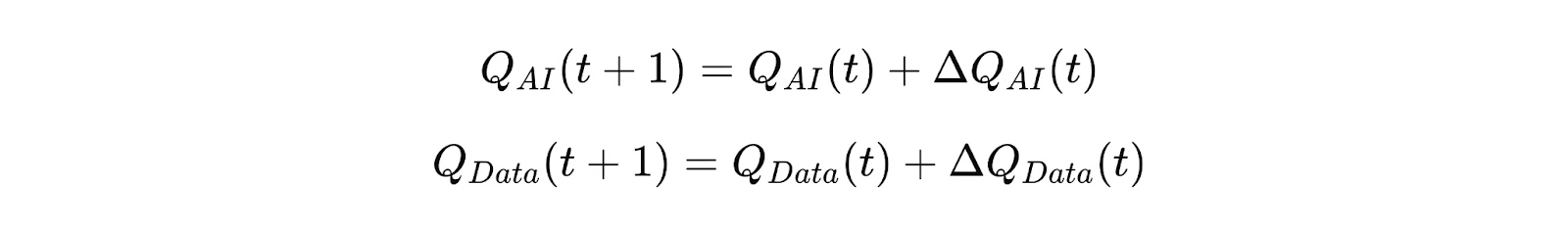
Here’s the idea: when moving from poor-quality data to good data, the impact on AI will be substantial (and vice versa). However, as data improves further—say, from great to exceptional—the incremental quality improvement diminishes significantly.
This leads us to define ΔQ(t), which captures the diminishing returns of improvement.
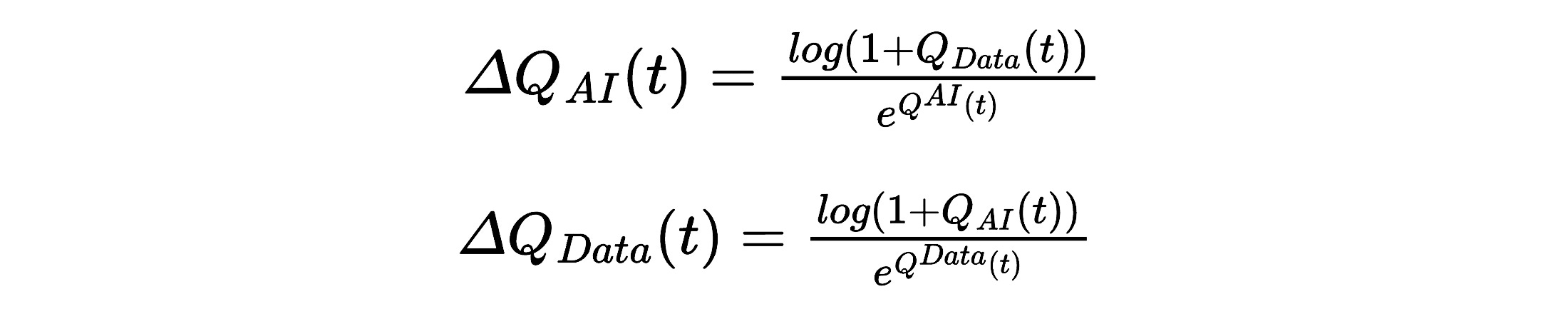
Visualizing the Concept
Admittedly, a formula isn’t always the clearest way to explain a concept, so here’s a more visual representation:
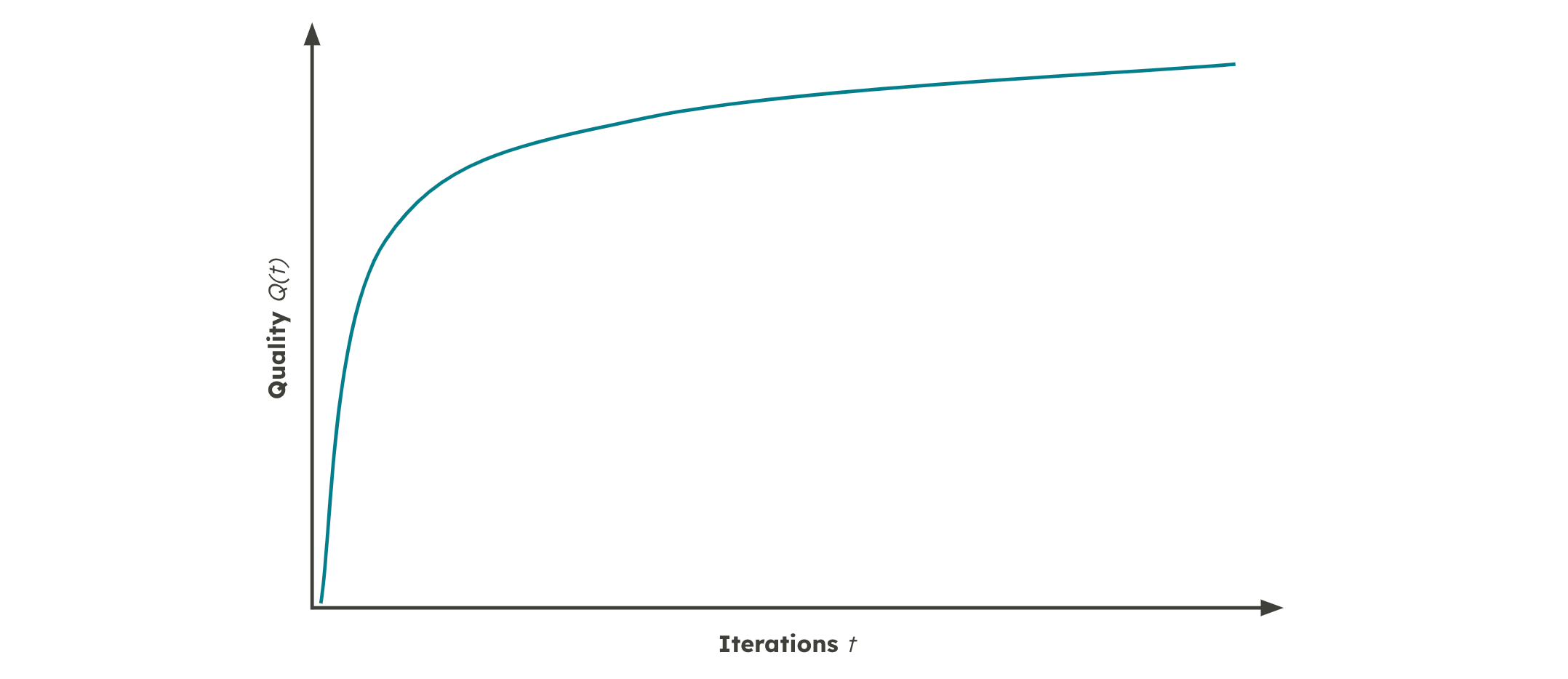
From this illustration, it’s clear that moving from “crappy” to “good” leads to significant quality improvements, while the journey from “good” to “great” brings smaller, incremental gains.
On a side note, even though AI and data are closely linked in improving one another, their quality improvement likely doesn’t follow identical formulas—contrary to what is suggested in my over simplified approach.
And that’s okay! I’m not claiming to publish a research paper here—this is more of a thought exercise. If anyone out there feels inspired to dive deeper into this, I’d love to see what they come up with.
Focus on your Data and AI Strategy—Don’t Get Lost Trying to Achieve Perfection
🔑 Why did I put this together? If there’s one takeaway from this post, it’s this: yes, data matters for AI. The better your data, the better your AI. But chasing perfect data isn’t the answer.
Pouring all your resources into achieving perfect data quality will drain an exponential amount of money with diminishing returns. At some point, your results will plateau, no matter how much more effort you put in.
Where is the right balance? Unfortunately, once again, I don’t have the exact formula. It will depend on several factors, including your budget, resources, expertise, and time—not to mention a few other variables unique to your situation.
Synthetic data is artificially generated data designed to resemble real data in structure and behavior, while not containing any actual data from the original source.